
Este artículo describe paso a paso la forma de crear una memoria de traducción a partir de un corpus paralelo. El recurso final puede ser de gran utilidad para el traductor, especialmente si trabaja con textos legales, aunque el procedimiento le puede servir a traductores que trabajan con otro tipo de documentos.
Por Miguel A. Ríos: [email protected]
Si eres usuario de programas de traducción asistida por computadora (TAC), puedes utilizar el corpus de la legislación de la Comisión Europea como memoria de traducción. Gracias al volumen de este corpus paralelo (más de 40 millones de palabras en inglés y más de 10 millones en español, por ejemplo), los archivos se pueden utilizar como base para aplicaciones de escritura predictiva, por ejemplo los diccionarios autosuggest de Trados o su más reciente función de sugerencias de fragmentos que viene en la versión 2017. Los 22 idiomas del corpus paralelo son: búlgaro, croata, checo, danés, holandés, inglés, estonio, alemán, griego, finlandés, francés, irlandés, húngaro, italiano, letón, lituano, maltés, polaco, portugués, rumano, eslovaco, esloveno, español y sueco. Haz clic aquí para descargar las estadísticas del corpus en PDF.
Los pasos para habilitar el corpus de la legislación europea como memoria de traducción para utilizar con programas TAC son los siguientes:
- Descargar los archivos TMX creados por la Comisión Europea
- Extraer la combinación de idiomas requerida de la biblioteca de archivos TMX
- Importar el archivo TMX a una memoria de traducción vacía
- Actualizar la memoria de traducción a Trados 2017
1. Descargar archivos multilingües compilados por la Comisión Europea (10 a 15 minutos)
La extensión .tmx hace referencia a un tipo de archivo creado para facilitar el intercambio de información entre traductores y agencias que utilizan programas TAC. Este formato se puede utilizar en los diferentes programas TAC utilizados por traductores.
Desde 2007, la Comisión Europea liberó el corpus multilingüe del Acquis Communautaire (acervo comunitario) para acceso público a través de su Dirección General de Traducción (DGT). El Aquis consiste en la esencia jurídica de la Unión Europea, es decir las normas, legislación y resoluciones que regulan el funcionamiento legal de la Unión Europea. En cuanto a la memoria de traducción, se trata del conjunto de textos (corpus) del Aquis con millones de enunciados (segmentos) alineados en 24 idiomas. La biblioteca de archivos se puede descargar de diversos sitios web, pero la fuente original está en el EU Science Hub, donde es posible descargar ediciones desde 2007.
Para tener el corpus completo es necesario descargar todos los archivos comprimidos (.zip), nueve en total para la edición de 2017.
2. Extraer la combinación de idiomas requerida (10 minutos)
El siguiente paso es extraer los archivos necesarios para crear la memoria específica en dos de los 24 idiomas del corpus.

Esto se logra con una sencilla aplicación de extracción (TMXtract.jar) que se puede descargar del mismo sitio. La aplicación se puede también descargar aquí.
La aplicación se debe guardar en la misma carpeta en la que se ubican los nueve archivos comprimidos del corpus. Una vez descargada en esa ubicación, haz clic en la aplicación para abrir la interfaz:
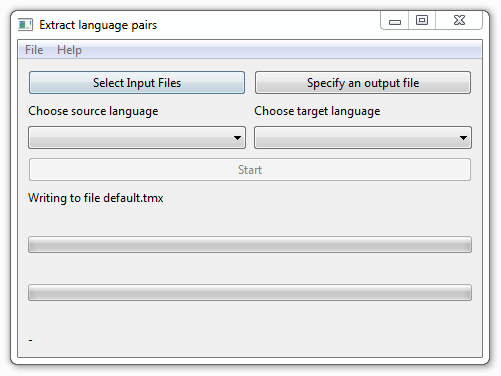
En “Select input files” hay que seleccionar los archivos comprimidos:
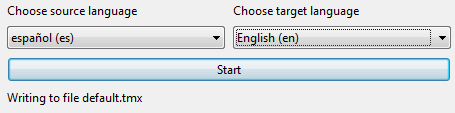
Finalmente, selecciona los idiomas de entrada y de salida y haz clic en “Start”:
Paso opcional: Los archivos TMX que se generan son bastante grandes: 460 MB para la combinación español-inglés. Dependiendo de la capacidad de procesamiento de tu PC, la memoria de traducción resultante puede ser demasiado grande. En mi caso (procesador Intel Core i34030U de 1.9 GHz), Trados tarda mucho en buscar resultados con la memoria final creada a partir del archivo TMX, así que en algunas computadoras puede ser conveniente generar un archivo TMX a partir de cada archivo comprimido para importarlos uno a uno a la memoria hasta encontrar la "masa crítica" de unidades de traducción que soporta tu sistema.
Así es como se ve mi carpeta con el archivo TMX completo y los archivos TMX extraídos individualmente con la aplicación TMXtract.jar:
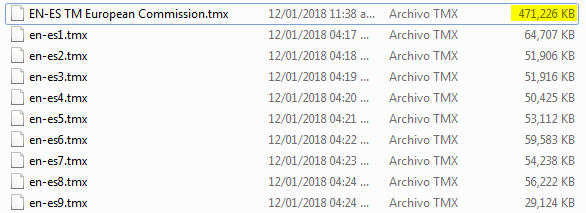
Selecciona individualmente cada archivo en la aplicación de extracción (TMXtract.jar):
3. Importar el archivo TMX a una memoria de traducción (20 a 30 minutos)
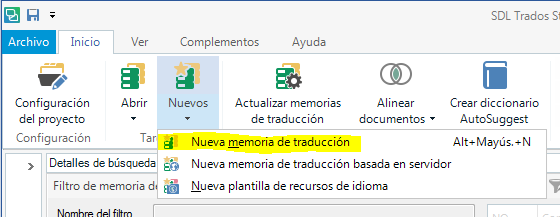
Estos archivos TMX están listos para importar a una memoria de traducción. A partir de aquí vamos a describir el proceso con SDL Trados Studio 2017. Para importar el archivo primero hay que crear una memoria de traducción vacía. Esto se lleva a cabo en la vista Memorias de Traducción:
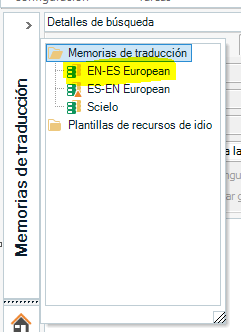
Una vez creada la memoria, hay que abrirla en el panel de la izquierda dentro de la vista Memorias de Traducción:
Haz doble clic en la memoria que acabas de crear para que se abra, y en el listón de funciones de la parte superior de la interfaz de Trados haz clic en importar e indícale al programa la ruta hasta el archivo o archivos TMX que creaste en el paso no 2 (extracción bilingüe con la aplicación TMXtract.jar).
Importa el archivo TMX que creaste en el Paso 2, o importa uno por uno los archivos individuales a la nueva memoria de traducción.
Una vez finalizado este proceso, la memoria está lista para utilizar con Trados Studio 2015 o versiones anteriores. Los pasos a seguir desde aquí con esas versiones son asociar la memoria a algún proyecto para aprovechar las coincidencias parciales o completas o crear un diccionario autosuggest.
4. Actualizar memoria a Trados Studio 2017 (2 horas por combinación de idiomas)
Si ya tienes la versión 2017 de Trados Studio, el siguiente paso es actualizar tu memoria para poder utilizar la función de coincidencias de fragmento (fragment matches). Esta nueva función de Studio 2017 es básicamente un diccionario autosuggest que no requiere el mínimo de 10,000 unidades de traducción para generar sugerencias, además de que no se necesita generar el archivo de diccionario autosuggest (*.bpm) porque Trados jala las sugerencias directamente desde tu memoria de traducción.
Si ya tienes la versión 2017 de Trados Studio, el siguiente paso es actualizar tu memoria para poder utilizar la función de coincidencias de fragmento (fragment matches). Esta nueva función de Studio 2017 es básicamente un diccionario autosuggest que no requiere el mínimo de 10,000 unidades de traducción para generar sugerencias, además de que no se necesita generar el archivo de diccionario autosuggest (*.bpm) porque Trados jala las sugerencias directamente desde tu memoria de traducción.
Si creaste la memoria con el archivo TMX que se genera con los nueve archivos comprimidos, el proceso va a tardar un par de horas (más o menos, dependiendo de la capacidad de procesamiento de tu PC). Durante este proceso, el tamaño de la memoria de traducción aumenta considerablemente: 3.17 GB para la combinación inglés-español, en comparación con los 617 MB después de importar el TMX y antes de la actualización a Studio 2017.
Cuando se agrega una memoria de traducción a un proyecto de Trados 2017, la memoria va a aparecer inicialmente como no actualizada; el software hace la advertencia mediante un triangulito naranja que aparece sobrepuesto a la memoria. Así es como se ve en la ventana de Configuración de Proyectos, pestaña Memorias de Traducción y Traducción automática:

Selecciona la memoria no actualizada (con triangulito) y haz clic en "actualizar". El proceso tarda un par de horas.
Como mencioné anteriormente, mi computadora tiene problemas para buscar con rapidez suficiente las coincidencias de fragmento, de modo que tarda más en buscar que en lo que traduzco el fragmento. Si te sucede algo similar y no estás planeando escalar tu equipo, puedes crear una memoria no tan grande utilizando los archivos TMX individuales extraídos con TMXtract.jar.





